TAda! Temporally-Adaptive Convolutions for Video Understanding
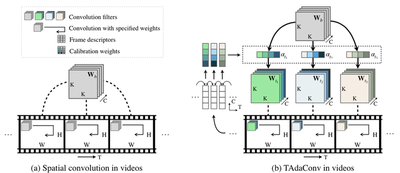
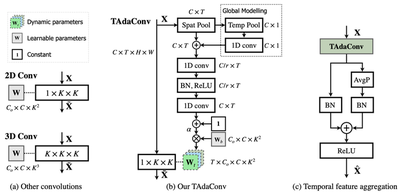
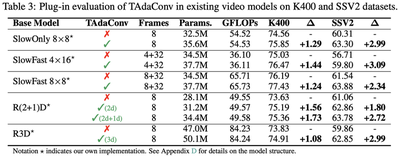
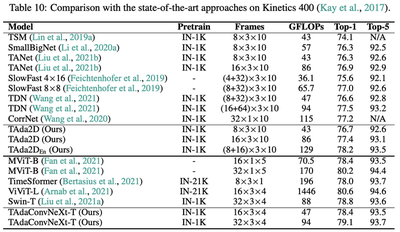
Spatial convolutions are widely used in numerous deep video models. It fundamentally assumes spatio-temporal invariance, i.e., using shared weights for every location in different frames. This work presents Temporally-Adaptive Convolutions (TAdaConv) for video understanding, which shows that adaptive weight calibration along the temporal dimension is an efficient way to facilitate modelling complex temporal dynamics in videos. Specifically, TAdaConv empowers the spatial convolutions with temporal modelling abilities by calibrating the convolution weights for each frame according to its local and global temporal context. Compared to previous temporal modelling operations, TAdaConv is more efficient as it operates over the convolution kernels instead of the features, whose dimension is an order of magnitude smaller than the spatial resolutions. Further, the kernel calibration brings an increased model capacity. We construct TAda2D and TAdaConvNeXt networks by replacing the 2D convolutions in ResNet and ConvNeXt with TAdaConv, which leads to at least on par or better performance compared to state-of-the-art approaches on multiple video action recognition and localization benchmarks. We also demonstrate that as a readily plug-in operation with negligible computation overhead, TAdaConv can effectively improve many existing video models with a convincing margin.
# In https://github.com/alibaba/EssentialMC2/papers/ICLR2022-TAdaConv
# 1. copy models/module_zoo/ops/tadaconv.py somewhere in your project
# and import TAdaConv2d, RouteFuncMLP
from tadaconv import TAdaConv2d, RouteFuncMLP
class Model(nn.Module):
def __init__(self):
...
# 2. define tadaconv and the route func in your model
self.conv_rf = RouteFuncMLP(
c_in=64, # number of input filters
ratio=4, # reduction ratio for MLP
kernels=[3,3], # list of temporal kernel sizes
)
self.conv = TAdaConv2d(
in_channels = 64,
out_channels = 64,
kernel_size = [1, 3, 3], # usually the temporal kernel size is fixed to be 1
stride = [1, 1, 1], # usually the temporal stride is fixed to be 1
padding = [0, 1, 1], # usually the temporal padding is fixed to be 0
bias = False,
cal_dim = "cin"
)
...
def self.forward(x):
...
# 3. replace 'x = self.conv(x)' with the following line
x = self.conv(x, self.conv_rf(x))
...

Citation
@inproceedings{huang2021tada,
title={TAda! Temporally-Adaptive Convolutions for Video Understanding},
author={Huang, Ziyuan and Zhang, Shiwei and Pan, Liang and Qing, Zhiwu and Tang, Mingqian and Liu, Ziwei and Ang Jr, Marcelo H},
booktitle={{ICLR}},
year={2022}
}